
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 예약
- appspec
- 2 > /dev/null
- 네이티브쿼리
- docker명령어
- 추후정리
- ㅔㄴ션
- 메소드명
- querydsl
- EC2
- AuthenticationEntryPoint
- Query
- 컨테이너실행
- 검색
- application.yml
- appspec.yml
- 테스트
- subquery
- MySQL
- WeNews
- 포트
- 적용우선순위
- 외부키
- 테스트메소드
- 커밋메세지수정
- 참조키
- 서브쿼리
- 메세지수정
- ubuntu
- foreignkey
- Today
- Total
제뉴어리의 모든것
[Section2] [관계형 데이터베이스] 데이터베이스 정규화 [추후 정리] 본문
데이터 정규화 이전에 알아야할 개념들
- 이상 현상 (Anomaly)
- 삽입 이상 (Insertion Anomaly)
- 갱신 이상 (Update Anomaly)
- 삭제 이상 (Deletion Anomaly) - 데이터 무결성 (Data integrity)
- 개체 무결성(Entity integrity)
- 참조 무결성(Referential integrity)
- 도메인 무결성(Domain integrity)
- Null무결성(Null integrity)
- 고유 무결성 (Unique integrity)
- 키 무결성 (Key integrity)
- 관계 무결성 (Relationship integrity) - 데이터 중복 (Data redundancy)
- 함수적 종속성 (Functional Dependency)
- 부분 함수적 종속성 (Partial Functional Dependency)
- 완전 함수적 종속성 (Full Functional Dependency)
이상 현상 (Anomaly)
릴레이션에서 일부 속성들의 종속이나 데이터의 중복으로 인해 데이터 조작시 불일치가 발생하는 것을 말합니다. 이상의 종류에는 삽입이상, 삭제이상, 갱신 이상이 있습니다.
그냥 테이블이 잘못 설계되 있어서 데이터 조작시 (입력, 삭제, 수정) 이상한 상황 이라고 생각하자.
- 삽입 이상
꼭 삽입이 되야하는 데이터임에도 불구하고, 삽입을 할 수 없는 상황을 말한다.
만약 교수라는 테이블이 있다.
그곳에 만약 교수의 정보에 관한 필드 이외에 "과목"이란 필드가 있다면,
그리고 교수 테이블에 모든 필드가 NN (NotNull)이라면, 새로운 교수가 왔음에도
교수 테이블에는 신임 교수를 추가 할 수가 없다.
이런 경우, NotNull을 해제 할 수도 있지만,
정규화를 진행하여 "교수" 테이블에는 한 교수에 대한 인적 사항만 필드로 쓰이고,(과목 필드 삭제)
"과목" 이란 테이블을 만들어서 "교수" 테이블의 PK와 "과목" 이란 테이블의 PK를 참조하여 두개의 필드를 PK로 가지는 "수업"이란 테이블을 만드는것이 하나의 해답이라고 할 수 있겠다. - 갱신 이상
중복 데이터 중 일부만 수정(갱신) 되어 같은 내용의 데이터임에도 불일치가 발생 하는 것을 말한다. - 삭제 이상
삭제할 때 원하지 않는 데이터까지 함께 삭제되어 데이터 손실이 발생할 수 있는 경우를 삭제 이상이라고 말한다.
만약 어떤 학교의 데이터베이스에는 "학생"이란 테이블만 있고, 그 테이블의 필드로 "학번" , "이름", "과목" 이 있다.
그리고 여러 학생들 중"제뉴어리맨"이라는 학생이 혼자서 "물리"라는 과목을 수강하여 "학생" 테이블에는 아래와 같이 레코드가 존재하는 상황에서,
[학번] [이름] [과목]
101 제뉴어리맨 물리
:
:
제뉴어리맨 학생의 레코드가 삭제된다면,
어디에서도 "물리"라는 데이터를 찾아볼 수 없을것이다.
이런 상황이 삭제 이상이다.
데이터 무결성 (Data integrity)
데이터 무결성은 데이터의 정확성, 일관성, 유효성이 유지되는 것을 의미함.
쉽게 말해, 레코드간에 구별되는 기본키(pk)는 유니크해야하고 null일 수 없으며,
그 pk는 다른곳에서 fk로 쓰일 수 있는데, 이때 fk는 아예 null, 이거나 참조 할 수 있어야한다.
fk로 지정된 pk를 참조 할 수 없어선 안된다. 그리고 각 필드의 값을 넣을때, 정해진 타입으로 넣어야한다 등등
일반 상식적인 이야기들이다.
참조 : https://cocoon1787.tistory.com/778
데이터 중복 (Data redundancy)
한 시스템이 같은 내용의 데이터가 여러 파일에 중복된 채 저장되어 관리되는것. 데이터 중복성은 한 데이터가 수정되면 중복된 데이터들을 모두 수정해야하는 불편함을 주며, 만일 일부만 수정되었을 경우 불일치성을 야기합니다. 또 저장공간의 낭비도 야기하게 됩니다.
함수적 종속성 (Functional Dependency)
한 릴레이션 안의 속성 간에 특정 속성값이 함수적으로 다른 속성 값을 결정하는 종속관계를 뜻합니다. 쉽게 A 속성을 알면 다른 속성 B, C를 알 수 있게 되는 관계를 함수 종속성이라고 합니다.
그리고 이때, A속성을 결정자. B, C 속성을 종속자 라고 하며,
A -> B, C 라고 표현한다.
- 함수적 종속성의 정리
이상현상이 발생한 원인은 하나의 릴레이션에 많은 속성을 무리하게 담아놓았기 때문입니다.
따라서 릴레이션을 분해해야 하는데, 분해해가는 과정을 정규화라고 합니다.
그러면 어떻게 분해해야 할까요?
⇒ 연관성이 높은 속성끼리 묶어서 릴레이션을 분해해가야 합니다.
그러면 어떻게 연관성이 높은지 알 수 있을까요?
⇒ 함수 종속성을 통해 알 수 있습니다.
그러면 함수 종속성이란?
⇒ 속성 A에 따라 속성 B가 결정되는 관계. (예: 학번을 알면 이름, 전화번호가 유일한 값으로 결정되게 됩니다.)
그래서 결론적으로
이상현상을 방지하려면 속성 사이의 연관관계, 즉 종속성(dependency)를 분석하여, 하나의 릴레이션에는 하나의 종속성만 표현되도록 릴레이션을 분할하면 됩니다.
자세한 내용은 아래의 블로그를 참조하자. 매우 잘 정리가 되어 있다.
참조: https://deep-deep-deep.tistory.com/162 [딥딥딥:티스토리]
데이터베이스 정규화 (Database Normalization)
데이터베이스 정규화의 정의는 아래와 같다.
관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화(Normalization)라고 한다. 데이터베이스 정규화의 목표는 이상이 있는 관계를 재구성하여 작고 잘 조직된 관계를 생성하는 것에 있다. 일반적으로 정규화란 크고, 제대로 조직되지 않은 테이블들과 관계들을 작고 잘 조직된 테이블과 관계들로 나누는 것을 포함한다.
예를들어, 테이블들을 필요에 의해 설계하다 보니 중복되는 필드가 있고 이런경우,
중복되는 두 테이블에서 필드를 아예 제외시키고 따로 테이블을 만든다는 것이다.
즉, 구조상 문제가 있는 데이터베이스의 테이블들을 쪼개서 나눈다는 의미.
정규화 방법
1. 1차 정규화 (1NF)
1차 정규화 된 테이블은 각 로우마다 컬럼의 값이 1개씩만 있어야 합니다. 이를 컬럼이 원자값(Atomic Value)를 갖는다고 한다. 즉, 아래와 같이 Subject 필드의 값이 Biology, Maths 와 같이 두개의 값이 존재해선 안된다는것이다.
그리고 현재 구조상이라면 아마 Subject 필드의 값은 가변적이다. 학생이 수업을 더 들을 수록 얼마나 더 늘어날지 모른느것이다. 그러므로 잘못 설계된 테이블이다.
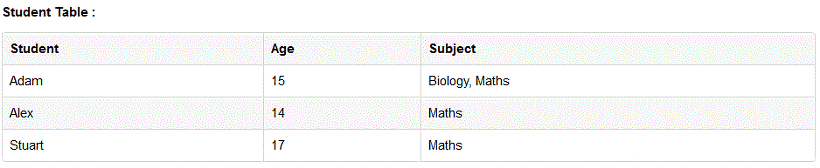
위의 정보를 표현하고 싶은 경우 이렇게 한 개의 로우를 더 만들게 됩니다. 결과적으로 1차 정규화를 함으로써 데이터 redundancy는 더 증가하였습니다. 데이터의 논리적 구성을 위해 이 부분을 희생하는 것으로 볼 수 있습니다.
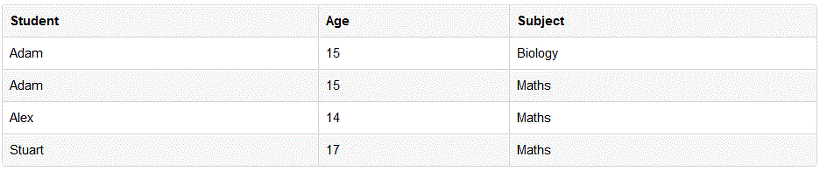
그러므로, 1차 정규화는! 각 필드의 값을 원자값으로!
2. 2차 정규화 (2NF)
2차 정규화부터가 본격적인 정규화의 시작이라고 볼 수 있습니다. 2차 정규형은 테이블의 모든 컬럼이 완전 함수적 종속을 만족하는 것입니다. 이게 무슨 말이냐면 기본키중에 특정 컬럼에만 종속된 컬럼(부분적 종속)이 없어야 한다는 것입니다. 위 테이블의 경우 기본키는 (Student, Subject) 두 개로 볼 수 있습니다. 이 두 개가 합쳐져야 한 로우를 구분할 수가 있습니다. 근데 Age의 경우 이 기본키중에 Student에만 종속되어 있습니다. 즉, Student 컬럼의 값을 알면 Age의 값을 알 수 있습니다. 따라서 Age가 두 번 들어가는 것은 불필요한 것으로 볼 수 있습니다.
Student Table

Subject Table
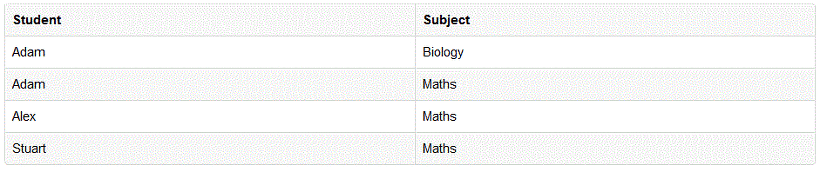
이렇게 student의 속성에만 종속되는 필드를 student 필드와 따로 테이블로 쪼갰고,
Subject 테이블에는 Student, Subject 필드만 남아서 불필요하게 계속 반복됬던 Age 필드를 제거하였다.
데이터베이스 공간의 낭비를 줄이고, 데이터 삽입, 갱신, 삭제 시 발생할 수 있는 문제점들을 방지하였다.
그러므로 2차 정규화는 여러 PK가 존재시, 특정 PK에게만 종속되는 필드는 특정 PK와 특정 필드만 빼서 테이블을 따로 정의! (반복 데이터를 따로 테이블화)
3. 3차 정규화 (3NF)
2차 정규화를 만족하면서, 테이블 내의 모든 속성이 기본 키에만 의존하며, 다른 후보 키에 의존하지 않는다.
이행함수 종속이 존재 하지 않는다.
말이 어려우니 아래의 예시를 보자.
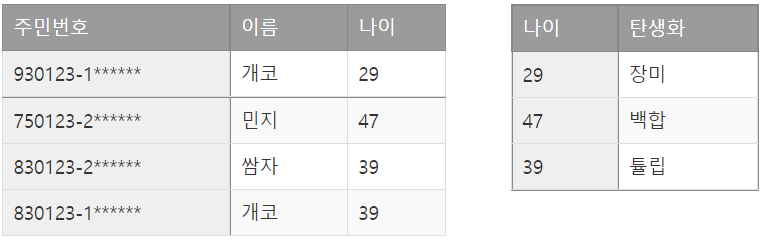
만약 아래와 같은 테이블이 있다.
| 주민번호 | 이름 | 나이 | 탄생화 |
| 930123-1****** | 개코 | 29 | 장미 |
| 750123-2****** | 민지 | 47 | 백합 |
| 830123-2****** | 쌈자 | 39 | 튤립 |
| 830123-1****** | 개코 | 39 | 튤립 |
pk는 주민번호입니다. 주민번호가 이름, 나이, 탄생화를 모두 결정합니다.
그런데 나이도 탄생화를 결정하네요.
함수 종속을 따져보면
X(주민번호) -> Y(나이), Y(나이) -> Z(탄생화) 에 의해 X(주민번호) -> Z(탄생화) 라는 관계가 성립되네요.
이러한 경우를 이행함수 종속이라고 합니다. 3정규형에서는 이행함수 종속을 제거해야합니다.
위와 같이 테이블을 나눌수 있다.
즉, 모든 필드는 결국 PK에만 종속되어야 한다는 것이다.
4. BCNF (Boyce-Codd Normal Form)
[추후 정리]
출처:
https://3months.tistory.com/193 [Deep Play:티스토리]
https://developer111.tistory.com/82
데이터베이스 정규화(1차, 2차, 3차, BCNF 정규화)
안녕하세요. 오늘은 데이터베이스 정규화에 대해 알아보겠습니다. 이전 두 포스팅을 통해 키의 개념과 함수종속성에 대해 알아보았습니다. (아래 포스팅 참조.) https://developer111.tistory.com/78 [Databa
developer111.tistory.com
https://deep-deep-deep.tistory.com/161 [딥딥딥:티스토리]
'코드스테이츠 > 정리 블로깅' 카테고리의 다른 글
| [Section2] [관계형 데이터베이스] [Spring Core] Spring Framework 기본 2 (0) | 2022.08.10 |
|---|---|
| [Section2] [관계형 데이터베이스] [Spring Core] Spring Framework 기본 (0) | 2022.08.09 |
| [Section2] [네트워크] 웹 애플리케이션 작동원리 (0) | 2022.08.03 |
| [Section2] [코딩테스트 준비] 탐욕 알고리즘 (Greedy) (0) | 2022.07.29 |
| [Section2] [코딩 테스트 준비] 자료구조 - 의사코드 (0) | 2022.07.29 |


