
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- application.yml
- 예약
- appspec
- WeNews
- appspec.yml
- 테스트메소드
- 2 > /dev/null
- 네이티브쿼리
- 적용우선순위
- ㅔㄴ션
- AuthenticationEntryPoint
- 메세지수정
- 메소드명
- 서브쿼리
- ubuntu
- 검색
- MySQL
- 추후정리
- 참조키
- 테스트
- 커밋메세지수정
- foreignkey
- docker명령어
- Query
- EC2
- 포트
- 컨테이너실행
- subquery
- querydsl
- 외부키
- Today
- Total
제뉴어리의 모든것
Chapter 11. Collection Framework - 3 (컬랙션 프레임웍의 구현체의 대하여 - Set) 본문
Set 인터페이스 구현체
- HashSet
내부적으로 HashMap을 이용하여 구현된 구현체로써 Set 컬랙션의 특징대로 데이터들의 저장순서가 컬랙션 내부에서 보장되지 않는다.(순서 보장을 하고 싶다면 LinkedHashSet을 사용하여야한다) 그리고 Set의 다른 특징대로 중복을 허용하지 않으므로, HashSet 구현체의 메서드로 중복된 데이터를 add 하려 할때 실패 했음을 return값으로 보내준다.
- 특징
1. 저장 순서가 HashSet의 내부에 데이터 위치. 순서 보장 X
2. 데이터 중복 불가
3. 데이터가 중복 불가이지만 Integer 타입의 1과 String 타입의 "1" 은 구별되어 저장이 가능하다 - TreeSet
이진 검색 트리 라는 자료 구조 형태로 데이터를 저장, 관리하는 클래스이다.
- 특징
1. Set 인터페이스의 특징대로 데이터의 중복을 허용하지 않는다
2. 데이터가 자동으로 정렬되어 지므로 저장순서는 유지 되지 않는다.
3. TreeSet에 저장되는 객체는 Comparable (저장되는 객체 내부에 정의) 을 구현하던지 Comparator를 제공하여 두 객체간의 비교를 할 방법을 알려주어야 한다.
+ 이진트리란?
LinkedList처럼 실제 데이터를 가진 Node가 존재하고, 각 노드는 최대 두개 Node의 주소값을 가질 수 있다.
그리고 데이터의 검색 (읽기, 삽입, 삭제) 은 root라는 시작 노드를 기점으로 탐색하여 가능하다
-> 이진트리의 특징
1. 부모 노드의 왼쪽 자식 노드는 부모 노드보다 작은 값을 가진 노드가 위치하고, 부모 노드의 오른쪽 자식 노드는 부모 노드보다 큰 값이 위치한다. (우선 최초 들어오는 값이 root가 되어 그 다음 데이터들은 모두 최초 root를 기준으로 비교되어 위치한다)
2. 왼쪽 최하단의 값부터 오른쪽 최하단의 값까지 읽어오면 오름차순 정렬된 상태로 데이터를 얻을 수 있다.
3. 노드의 추가 삭제에 시간이 걸린다 (삭제된 노드와 연결된 노드들의 트리 구조를 재 구성 해야하므로)
4. 검색과 정렬에 유리하다.(저장된 값의 개수에 비례해서 검색시간이 증가하긴 하지만 데이터의 수가 10배가 증가해도 특정 값을 찾는데 비교횟수가 3~4번 정도밖에 증가 되지 않는다)
5. 단일값 검색과 범위검색이 매우 빠르다. (예를 들면 3 ~ 7 사이 범위의 값을 가져오기)

- HashSet의 대한 정리 -
HashSet
Set 인터페이스의 구현체 중 하나
데이터 중복 X
데이터 저장순서 X
HashSet의 메서드
주요한 메서드들은 검색만 하여도 쉽게 알 수 있으므로, 메서드가 잘 정리 되있는 블로그를 참조하여 대체하고 특별하거나 모르고 지나칠 수 있는 메서드만 추려내겠다.
- 유의 메서드
: HashSet (Collection c) - 주어진 컬랙션을 HashSet로써 생성한다.
: HashSet (int initialCapacity) - 주어진 값으로 HashSet의초기 용량을 설정한다
: HashSet (int initialCapacity, float loadFactor) - 초기 용량과 load factor를 지정하는 생성자
+ load factor란 컬랙션 클래스에 저장공간이 가득 차기 전에 미리 용량을 확보하는 것으로, 0.8로 설정하면 용량의 80%가 채워졌을때 용량이 두배로 늘어난다. 기본값은 0.75이다. - 관련 코드
package ch11.practice.subPractice;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class HashsetPractice {
public static void main(String[] args) {
Set set = new HashSet();
System.out.println(set.add(1)); //Integer형 1
System.out.println(set.add(2));
System.out.println(set.add(3));
System.out.println(set.add(1)); //1의 중복 add
System.out.println(set.add("1")); //String형 1
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
System.out.println();
}
}
- 결과 화면

결과로 보이다시피 출력값은 마치 1이 중복되어 저장된것 같지만, 이 두가지 각각 String 형과 Integer형이다.
그리고 중복된 Integer 1을 add 하였을때는 add되지 못하고 false를 반환한다. (이런 경우를 방지 하기 위하여, TreeSet 객체 생성시 Generic을 사용하여 매개변수 타입을 지정하여 주면 좋을것 같다)
- TreeSet의 대한 정리 -
TreeSet
이진 검색 트리라는 자료구조로 데이터를 관리하는 Set 인터페이스의 구현체 중 하나.
데이터 중복 X,
자동 정렬되므로 저장 순서 의미 없음.
TreeSet의 메서드
- 생성자
:TreeSet() - 기본 생성자
: TreeSet(Collection c) - 주어진 컬랙션을 저장하는 TreeSet 객체 생성
: TreeSet(Comparator comp) - 주어진 Comparator의 규칙으로 정렬된 TreeSet 객체 생성 - 메서드
: add(Object o)
: add(Collection c) - 컬랙션 자체를 저장
: first() - 정렬된 순서에서 첫번째 객체 반환
: last() -
: ceiling(Object o)
: floor(Object o)
: higher(Object o)
: lower(Object o)
: subSet(Object fromElement, Object toElement)
: headSet(Object toElement)
: tailSet(Object fromElement) - 관련 코드 1 (문자열 요소들에서 범위 검색)
package ch11.ex;
import java.util.*;
class TreeSetEx1 {
public static void main(String[] args) {
TreeSet set = new TreeSet();
String from = "b";
String to = "d";
set.add("abcd");set.add("addd");set.add("batewr");set.add("ccde");
set.add("Addf");set.add("Cdfe");set.add("zzzzs");set.add("ddZXX");
set.add("Bddas");set.add("bbdz");set.add("tgfgfd");set.add("adx");
set.add("11asd");set.add("xcx");set.add(" dzzz"); set.add(" dzzzz");
set.add(" dz=");set.add("dzz");
System.out.println();
System.out.println("==원래 구조==");
System.out.println(set);
System.out.println("==원래 구조==");
System.out.println();
System.out.println("== from ~ to ==");
System.out.println("result1 : " + set.subSet(from, to));
System.out.println("== from ~ to ==");
System.out.println();
System.out.println("== from ~ dzzz ==");
System.out.println("result2 : " + set.subSet(from, to + "zzz"));
System.out.println("== from ~ dzzz ==");
System.out.println();
}
}
- 관련 코드 1 의 결과 화면
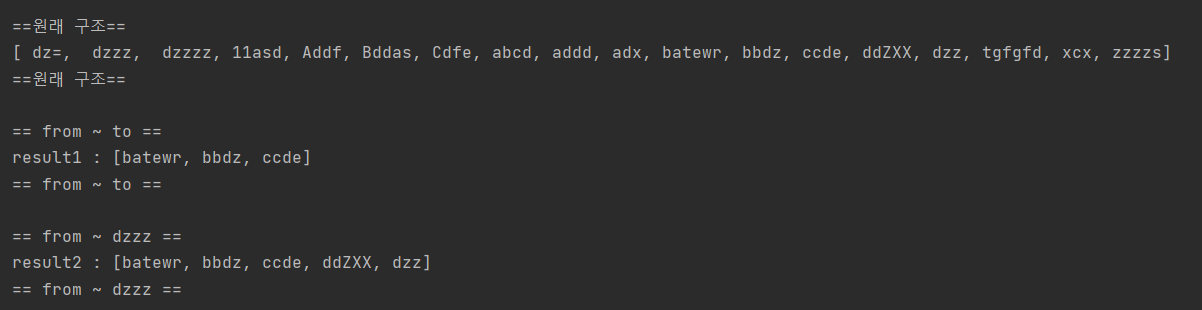
현재 Set에 저장된 원래 구조는 저장순서가 아닌 Tree 구조로 정렬된 모습이다.
from ~ to의 결과는 "b" ~ "d" 사이의 결과값인데,
참고로 문자열의 경우 문자의 코드값이 기준이 되는데,
b ~ d 사이라는 것은 -> b코드값 이상부터 ~ d 코드값 미만이라는 말이다.
+참고 사항으로 각 문자들의 코드값은 아래의 결과를 보면 알 수 있다
package ch11.ex;
class AsciiPrint{
public static void main(String[] args) {
char ch = ' ';
for(int i=0; i < 95; i++)
System.out.print(ch++);
System.out.println();
}
}

각 문자들의 아스키코드값이며, 맨 앞은 공백이다.
다시 본론으로 돌아와서
문자열의 범위를 검사하는 순서는 아래와 같다.
b ~ d 라는것은 문자열이 1개이므로 최초 첫글자의 범위만을 검사하는것이다.
그래서 요소들의 첫글자를 검사하여 b 이상 d 미만인 문자열들만 추려낸다.
그런데 "from ~ dzzz" 를 보면
b ~ dzzz 사이라는 것이다.
이것은 어떻게 범위를 탐색할까?
우선 탐색 시작범위는 여전히 b 이다 그렇다면
첫글자가 b 이상이여야 한다.
그런데 끝범위가 dzzz이다. 그리고 끝 범위는 이하가 아니라 미만이라고 하였다.
그리고 첫글자보다는 마지막글자가 더 깊이있는 탐색일 것이다.
그러므로 끝 글자가 탐색의 기준이 된다.
그래서 dzzz 중 dzz의 범위까지는 포함이고, 마지막 z의 미만이 되어야 하는것이다.
이런 이유로 위에 dzzz는 포함이 되지 못하였고, dzz는 포함이 될 수있었다.
dzzz가 dzz 보다 한글자를 더 디테일하고 검색을 하는데, dzz는 그 범위안에 이미 들어가는것이다.
그리고 dzzzz는 이미 dzzz의 마지막 z의 미만이라는 기준에서 넘치는 범위이다.
그러므로 포함되지 못하였다.
- 관련 코드 2 (정수 요소들 중 범위 검색)
package ch11.ex;
import java.util.*;
class TreeSetEx2 {
public static void main(String[] args) {
TreeSet set = new TreeSet();
int[] score = {80, 95, 50, 35, 45, 65, 10, 100};
for(int i=0; i < score.length; i++)
set.add(new Integer(score[i]));
System.out.println("50보다 작은 값 :" + set.headSet(new Integer(50)));
System.out.println("50보다 큰 값 :" + set.tailSet(new Integer(50)));
System.out.println("37보다 작은 값 :" + set.headSet(new Integer(37)));
}
}
- 관련 코드 2의 결과 화면

set.headSet -> 이 함수는 매개변수로 넘기는 객체를 기준인 Head노드로 삼겠다는것이니까 좌측 노드와 그 좌측 노드의 자식 노드들을 가져올 것이다. (그러므로 매개변수로 넘긴 객체보다 작은 값)
set.tailSet -> 이 함수는 매개변수로 넘기는 객체를 꼬리 노드로 삼으므로 본인보다 큰 값의 노드들을 가져올 것이다.
그리고, 50은 노드 (컬랙션에 추가된 요소) 이므로 개념적으로 이해가 가지만, 노드로써 존재하지 않는 37이란 값을 어떻게 가져오는지 아직 개념적으로 정확히 이해가 가진 않는다. 하지만 추측컨데, 37이라는 가상의 노드를 만들고 그 노드를 메서드에 따라 head로 삼을지 tail로 삼을지 결정하여 결과값을 가져오지 않을까 싶다...
'JAVA > 자바의정석' 카테고리의 다른 글
| Chapter 11. Collection Framework - 4 (컬랙션 프레임웍의 구현체의 대하여 - Map) (0) | 2022.07.12 |
|---|---|
| Chapter 11. Iterator, ListIterator, Enumeration (0) | 2022.07.10 |
| Chapter 11. Collection Framework - 2 (컬랙션 프레임웍의 구현체의 대하여 - List) (0) | 2022.07.09 |
| Chapter 7. 제어자 (0) | 2022.07.09 |
| Chapter 11. Collection Framework - 1 (컬랙션 프레임웍의 인터페이스에 대하여) (0) | 2022.07.04 |

